5 Converting to and from non-tidy formats
In the previous chapters, we’ve been analyzing text arranged in the tidy text format: a table with one-token-per-document-per-row, such as is constructed by the unnest_tokens() function. This lets us use the popular suite of tidy tools such as dplyr, tidyr, and ggplot2 to explore and visualize text data. We’ve demonstrated that many informative text analyses can be performed using these tools.
However, most of the existing R tools for natural language processing, besides the tidytext package, aren’t compatible with this format. The CRAN Task View for Natural Language Processing lists a large selection of packages that take other structures of input and provide non-tidy outputs. These packages are very useful in text mining applications, and many existing text datasets are structured according to these formats.
Computer scientist Hal Abelson has observed that “No matter how complex and polished the individual operations are, it is often the quality of the glue that most directly determines the power of the system” (Abelson 2008). In that spirit, this chapter will discuss the “glue” that connects the tidy text format with other important packages and data structures, allowing you to rely on both existing text mining packages and the suite of tidy tools to perform your analysis.
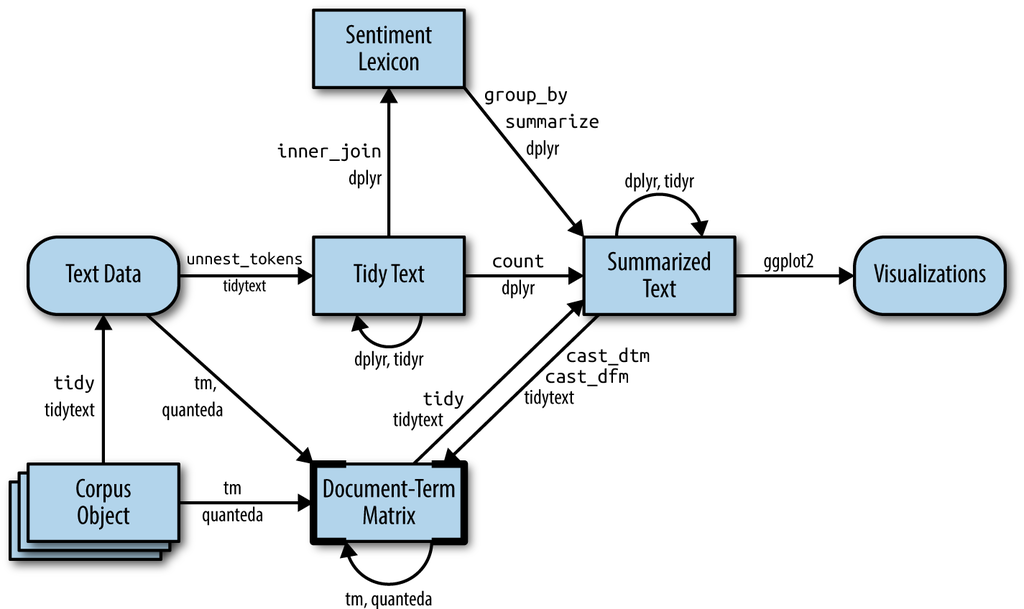
Figure 5.1: A flowchart of a typical text analysis that combines tidytext with other tools and data formats, particularly the tm or quanteda packages. This chapter shows how to convert back and forth between document-term matrices and tidy data frames, as well as converting from a Corpus object to a text data frame.
Figure 5.1 illustrates how an analysis might switch between tidy and non-tidy data structures and tools. This chapter will focus on the process of tidying document-term matrices, as well as casting a tidy data frame into a sparse matrix. We’ll also explore how to tidy Corpus objects, which combine raw text with document metadata, into text data frames, leading to a case study of ingesting and analyzing financial articles.
5.1 Tidying a document-term matrix
One of the most common structures that text mining packages work with is the document-term matrix (or DTM). This is a matrix where:
- each row represents one document (such as a book or article),
- each column represents one term, and
- each value (typically) contains the number of appearances of that term in that document.
Since most pairings of document and term do not occur (they have the value zero), DTMs are usually implemented as sparse matrices. These objects can be treated as though they were matrices (for example, accessing particular rows and columns), but are stored in a more efficient format. We’ll discuss several implementations of these matrices in this chapter.
DTM objects cannot be used directly with tidy tools, just as tidy data frames cannot be used as input for most text mining packages. Thus, the tidytext package provides two verbs that convert between the two formats.
-
tidy()turns a document-term matrix into a tidy data frame. This verb comes from the broom package (Robinson 2017), which provides similar tidying functions for many statistical models and objects. -
cast()turns a tidy one-term-per-row data frame into a matrix. tidytext provides three variations of this verb, each converting to a different type of matrix:cast_sparse()(converting to a sparse matrix from the Matrix package),cast_dtm()(converting to aDocumentTermMatrixobject from tm), andcast_dfm()(converting to adfmobject from quanteda).
As shown in Figure 5.1, a DTM is typically comparable to a tidy data frame after a count or a group_by/summarize that contains counts or another statistic for each combination of a term and document.
5.1.1 Tidying DocumentTermMatrix objects
Perhaps the most widely used implementation of DTMs in R is the DocumentTermMatrix class in the tm package. Many available text mining datasets are provided in this format. For example, consider the collection of Associated Press newspaper articles included in the topicmodels package.
library(tm)
data("AssociatedPress", package = "topicmodels")
AssociatedPress
#> <<DocumentTermMatrix (documents: 2246, terms: 10473)>>
#> Non-/sparse entries: 302031/23220327
#> Sparsity : 99%
#> Maximal term length: 18
#> Weighting : term frequency (tf)We see that this dataset contains 2246 documents (each of them an AP article) and 10473 terms (distinct words). Notice that this DTM is 99% sparse (99% of document-word pairs are zero). We could access the terms in the document with the Terms() function.
terms <- Terms(AssociatedPress)
head(terms)
#> [1] "aaron" "abandon" "abandoned" "abandoning" "abbott"
#> [6] "abboud"If we wanted to analyze this data with tidy tools, we would first need to turn it into a data frame with one-token-per-document-per-row. The broom package introduced the tidy() verb, which takes a non-tidy object and turns it into a tidy data frame. The tidytext package implements this method for DocumentTermMatrix objects.
library(dplyr)
library(tidytext)
ap_td <- tidy(AssociatedPress)
ap_td
#> # A tibble: 302,031 × 3
#> document term count
#> <int> <chr> <dbl>
#> 1 1 adding 1
#> 2 1 adult 2
#> 3 1 ago 1
#> 4 1 alcohol 1
#> 5 1 allegedly 1
#> 6 1 allen 1
#> 7 1 apparently 2
#> 8 1 appeared 1
#> 9 1 arrested 1
#> 10 1 assault 1
#> # ℹ 302,021 more rowsNotice that we now have a tidy three-column tbl_df, with variables document, term, and count. This tidying operation is similar to the melt() function from the reshape2 package (Wickham 2007) for non-sparse matrices.
Notice that only the non-zero values are included in the tidied
output: document 1 includes terms such as “adding” and “adult”, but not
“aaron” or “abandon”. This means the tidied version has no rows where
count is zero.
As we’ve seen in previous chapters, this form is convenient for analysis with the dplyr, tidytext and ggplot2 packages. For example, you can perform sentiment analysis on these newspaper articles with the approach described in Chapter 2.
ap_sentiments <- ap_td %>%
inner_join(get_sentiments("bing"), by = c(term = "word"))
ap_sentiments
#> # A tibble: 30,094 × 4
#> document term count sentiment
#> <int> <chr> <dbl> <chr>
#> 1 1 assault 1 negative
#> 2 1 complex 1 negative
#> 3 1 death 1 negative
#> 4 1 died 1 negative
#> 5 1 good 2 positive
#> 6 1 illness 1 negative
#> 7 1 killed 2 negative
#> 8 1 like 2 positive
#> 9 1 liked 1 positive
#> 10 1 miracle 1 positive
#> # ℹ 30,084 more rowsThis would let us visualize which words from the AP articles most often contributed to positive or negative sentiment, seen in Figure 5.2. We can see that the most common positive words include “like”, “work”, “support”, and “good”, while the most negative words include “killed”, “death”, and “vice”. (The inclusion of “vice” as a negative term is probably a mistake on the algorithm’s part, since it likely usually refers to “vice president”).
library(ggplot2)
ap_sentiments %>%
count(sentiment, term, wt = count) %>%
filter(n >= 200) %>%
mutate(n = ifelse(sentiment == "negative", -n, n)) %>%
mutate(term = reorder(term, n)) %>%
ggplot(aes(n, term, fill = sentiment)) +
geom_col() +
labs(x = "Contribution to sentiment", y = NULL)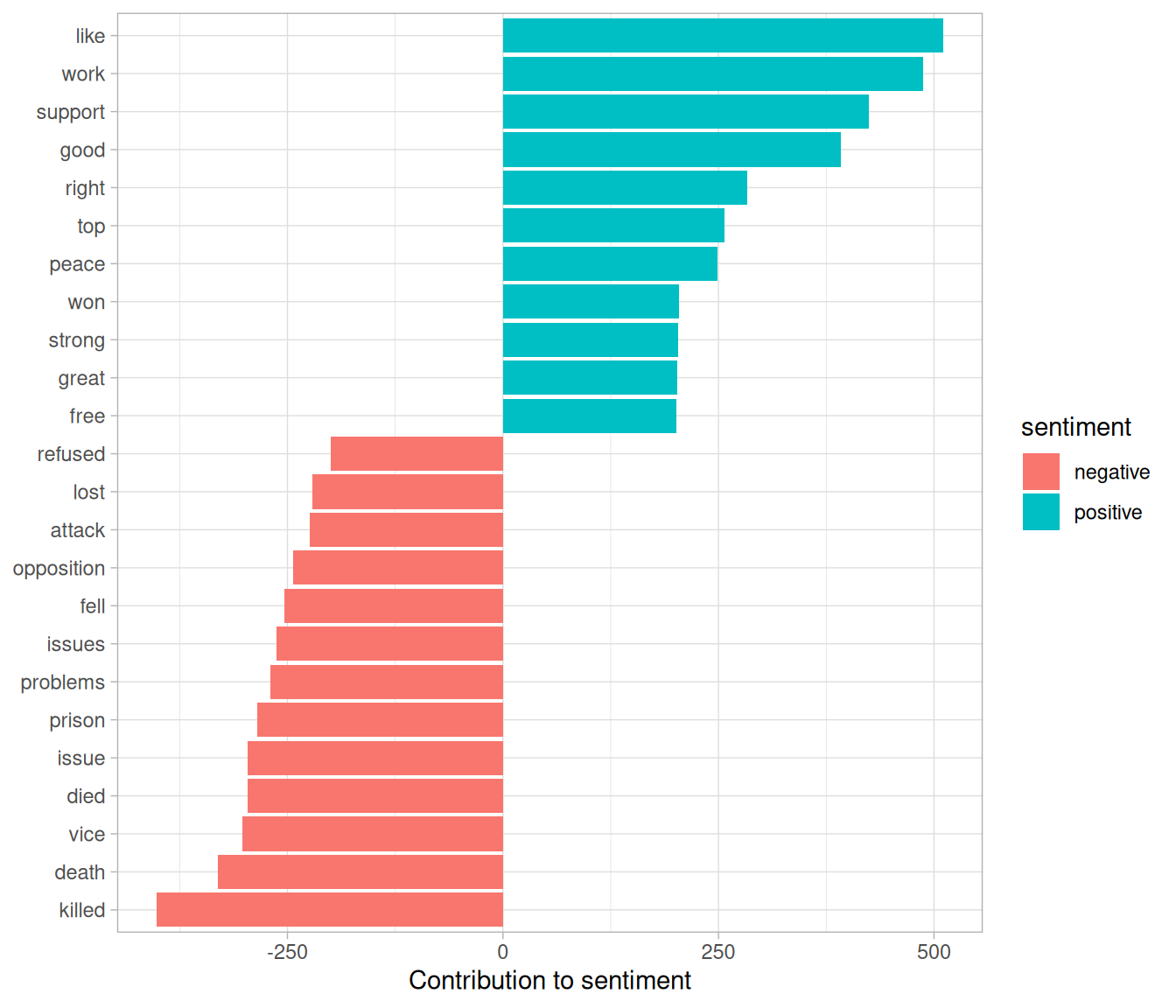
Figure 5.2: Words from AP articles with the greatest contribution to positive or negative sentiments, using the Bing sentiment lexicon
5.1.2 Tidying dfm objects
Other text mining packages provide alternative implementations of document-term matrices, such as the dfm (document-feature matrix) class from the quanteda package (Benoit and Nulty 2016). For example, the quanteda package comes with a corpus of presidential inauguration speeches, which can be converted to a dfm using the appropriate functions.
data("data_corpus_inaugural", package = "quanteda")
inaug_dfm <- data_corpus_inaugural %>%
quanteda::tokens() %>%
quanteda::dfm(verbose = FALSE)
inaug_dfm
#> Document-feature matrix of: 59 documents, 9,437 features (91.84% sparse) and 4 docvars.The tidy method works on these document-feature matrices as well, turning them into a one-token-per-document-per-row table:
inaug_td <- tidy(inaug_dfm)
inaug_td
#> # A tibble: 45,452 × 3
#> document term count
#> <chr> <chr> <dbl>
#> 1 1789-Washington fellow-citizens 1
#> 2 1797-Adams fellow-citizens 3
#> 3 1801-Jefferson fellow-citizens 2
#> 4 1809-Madison fellow-citizens 1
#> 5 1813-Madison fellow-citizens 1
#> 6 1817-Monroe fellow-citizens 5
#> 7 1821-Monroe fellow-citizens 1
#> 8 1841-Harrison fellow-citizens 11
#> 9 1845-Polk fellow-citizens 1
#> 10 1849-Taylor fellow-citizens 1
#> # ℹ 45,442 more rowsWe may be interested in finding the words most specific to each of the inaugural speeches. This could be quantified by calculating the tf-idf of each term-speech pair using the bind_tf_idf() function, as described in Chapter 3.
inaug_tf_idf <- inaug_td %>%
bind_tf_idf(term, document, count) %>%
arrange(desc(tf_idf))
inaug_tf_idf
#> # A tibble: 45,452 × 6
#> document term count tf idf tf_idf
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 1793-Washington arrive 1 0.00680 4.08 0.0277
#> 2 1793-Washington upbraidings 1 0.00680 4.08 0.0277
#> 3 1793-Washington violated 1 0.00680 3.38 0.0230
#> 4 1793-Washington willingly 1 0.00680 3.38 0.0230
#> 5 1793-Washington incurring 1 0.00680 3.38 0.0230
#> 6 1793-Washington previous 1 0.00680 2.98 0.0203
#> 7 1793-Washington knowingly 1 0.00680 2.98 0.0203
#> 8 1793-Washington injunctions 1 0.00680 2.98 0.0203
#> 9 1793-Washington witnesses 1 0.00680 2.98 0.0203
#> 10 1793-Washington besides 1 0.00680 2.69 0.0183
#> # ℹ 45,442 more rowsWe could use this data to pick four notable inaugural addresses (from Presidents Lincoln, Roosevelt, Kennedy, and Obama), and visualize the words most specific to each speech, as shown in Figure 5.3.
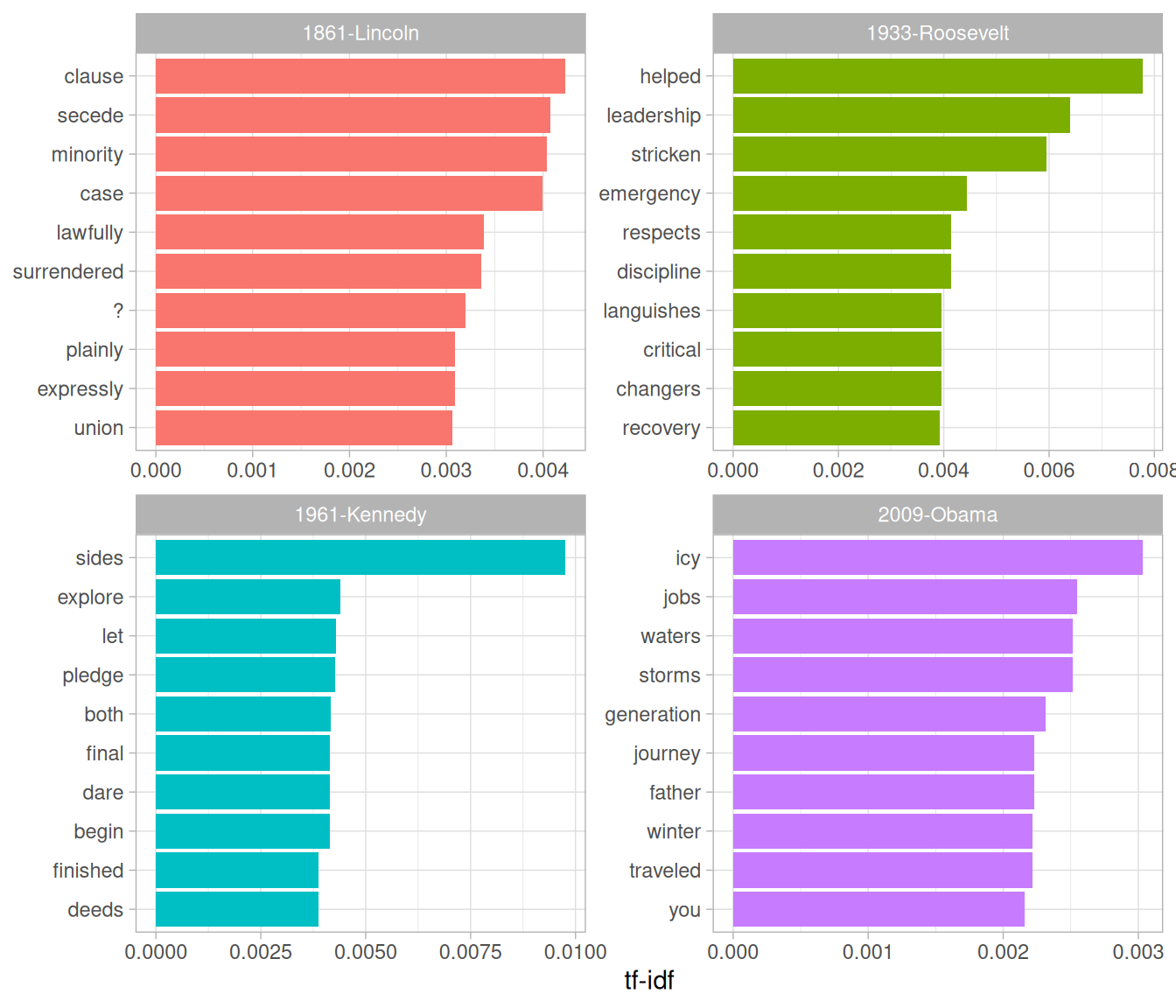
Figure 5.3: The terms with the highest tf-idf from each of four selected inaugural addresses. Note that quanteda’s tokenizer includes the ‘?’ punctuation mark as a term, though the texts we’ve tokenized ourselves with unnest_tokens() do not.
As another example of a visualization possible with tidy data, we could extract the year from each document’s name, and compute the total number of words within each year.
Note that we’ve used tidyr’s complete() function to
include zeroes (cases where a word didn’t appear in a document) in the
table.
library(tidyr)
year_term_counts <- inaug_td %>%
extract(document, "year", "(\\d+)", convert = TRUE) %>%
complete(year, term, fill = list(count = 0)) %>%
group_by(year) %>%
mutate(year_total = sum(count))This lets us pick several words and visualize how they changed in frequency over time, as shown in 5.4. We can see that over time, American presidents became less likely to refer to the country as the “Union” and more likely to refer to “America”. They also became less likely to talk about the “constitution” and foreign” countries, and more likely to mention “freedom” and “God”.
year_term_counts %>%
filter(term %in% c("god", "america", "foreign", "union", "constitution", "freedom")) %>%
ggplot(aes(year, count / year_total)) +
geom_point() +
geom_smooth() +
facet_wrap(~ term, scales = "free_y") +
scale_y_continuous(labels = scales::percent_format()) +
labs(y = "% frequency of word in inaugural address")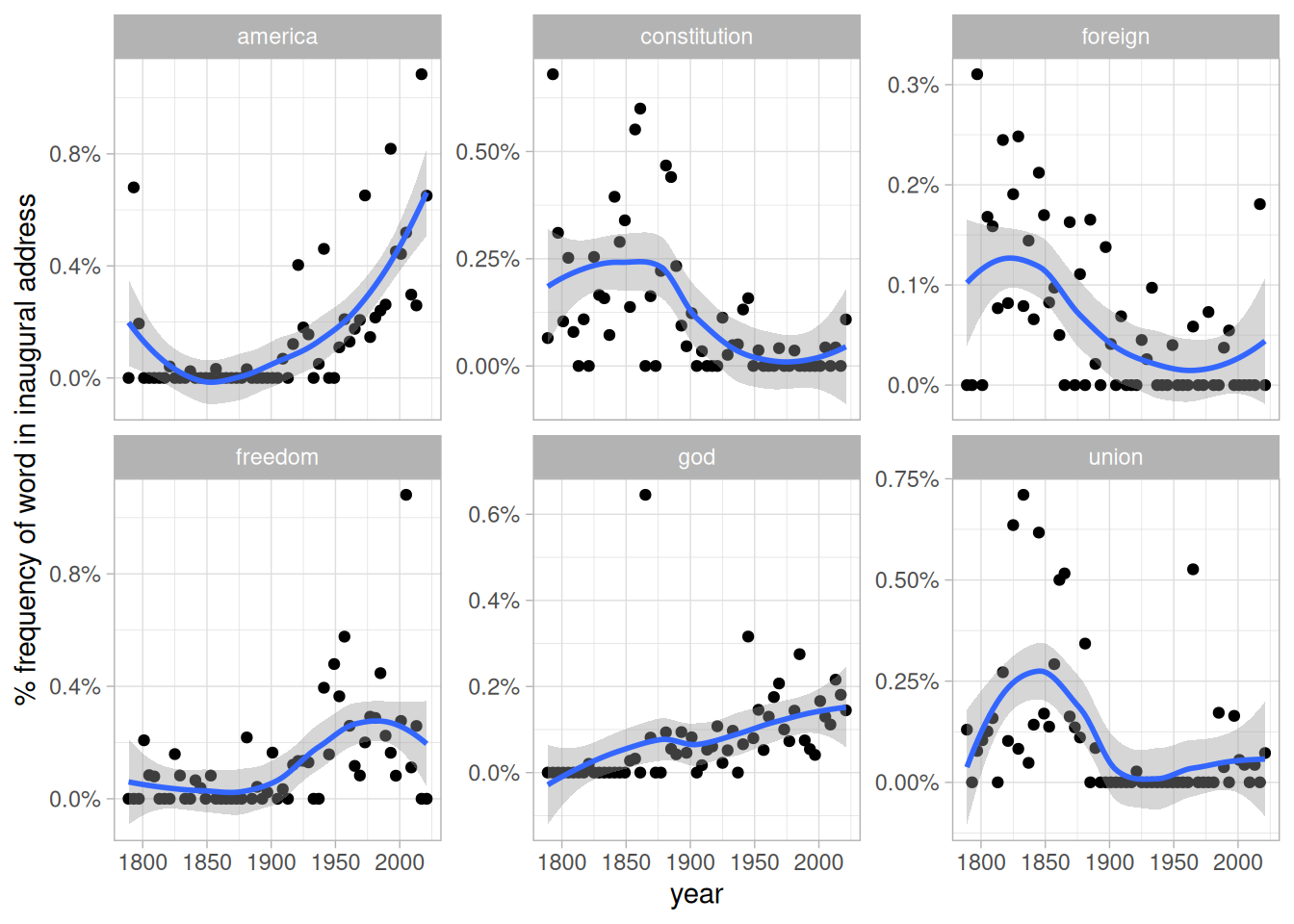
Figure 5.4: Changes in word frequency over time within Presidential inaugural addresses, for six selected terms
These examples show how you can use tidytext, and the related suite of tidy tools, to analyze sources even if their origin was not in a tidy format.
5.2 Casting tidy text data into a matrix
Just as some existing text mining packages provide document-term matrices as sample data or output, some algorithms expect such matrices as input. Therefore, tidytext provides cast_ verbs for converting from a tidy form to these matrices.
For example, we could take the tidied AP dataset and cast it back into a document-term matrix using the cast_dtm() function.
ap_td %>%
cast_dtm(document, term, count)
#> <<DocumentTermMatrix (documents: 2246, terms: 10473)>>
#> Non-/sparse entries: 302031/23220327
#> Sparsity : 99%
#> Maximal term length: 18
#> Weighting : term frequency (tf)Similarly, we could cast the table into a dfm object from quanteda’s dfm with cast_dfm().
ap_td %>%
cast_dfm(document, term, count)
#> Document-feature matrix of: 2,246 documents, 10,473 features (98.72% sparse) and 0 docvars.Some tools simply require a sparse matrix:
library(Matrix)
# cast into a Matrix object
m <- ap_td %>%
cast_sparse(document, term, count)
class(m)
#> [1] "dgCMatrix"
#> attr(,"package")
#> [1] "Matrix"
dim(m)
#> [1] 2246 10473This kind of conversion could easily be done from any of the tidy text structures we’ve used so far in this book. For example, we could create a DTM of Jane Austen’s books in just a few lines of code.
library(janeaustenr)
austen_dtm <- austen_books() %>%
unnest_tokens(word, text) %>%
count(book, word) %>%
cast_dtm(book, word, n)
austen_dtm
#> <<DocumentTermMatrix (documents: 6, terms: 14516)>>
#> Non-/sparse entries: 40378/46718
#> Sparsity : 54%
#> Maximal term length: 19
#> Weighting : term frequency (tf)This casting process allows for reading, filtering, and processing to be done using dplyr and other tidy tools, after which the data can be converted into a document-term matrix for machine learning applications. In Chapter 6, we’ll examine some examples where a tidy-text dataset has to be converted into a DocumentTermMatrix for processing.
5.3 Tidying corpus objects with metadata
Some data structures are designed to store document collections before tokenization, often called a “corpus”. One common example is Corpus objects from the tm package. These store text alongside metadata, which may include an ID, date/time, title, or language for each document.
For example, the tm package comes with the acq corpus, containing 50 articles from the news service Reuters.
data("acq")
acq
#> <<VCorpus>>
#> Metadata: corpus specific: 0, document level (indexed): 0
#> Content: documents: 50
# first document
acq[[1]]
#> <<PlainTextDocument>>
#> Metadata: 15
#> Content: chars: 1287A corpus object is structured like a list, with each item containing both text and metadata (see the tm documentation for more on working with Corpus documents). This is a flexible storage method for documents, but doesn’t lend itself to processing with tidy tools.
We can thus use the tidy() method to construct a table with one row per document, including the metadata (such as id and datetimestamp) as columns alongside the text.
acq_td <- tidy(acq)
acq_td
#> # A tibble: 50 × 16
#> author datetimestamp description heading id language origin topics
#> <chr> <dttm> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 <NA> 1987-02-26 15:18:06 "" COMPUT… 10 en Reute… YES
#> 2 <NA> 1987-02-26 15:19:15 "" OHIO M… 12 en Reute… YES
#> 3 <NA> 1987-02-26 15:49:56 "" MCLEAN… 44 en Reute… YES
#> 4 By Cal … 1987-02-26 15:51:17 "" CHEMLA… 45 en Reute… YES
#> 5 <NA> 1987-02-26 16:08:33 "" <COFAB… 68 en Reute… YES
#> 6 <NA> 1987-02-26 16:32:37 "" INVEST… 96 en Reute… YES
#> 7 By Patt… 1987-02-26 16:43:13 "" AMERIC… 110 en Reute… YES
#> 8 <NA> 1987-02-26 16:59:25 "" HONG K… 125 en Reute… YES
#> 9 <NA> 1987-02-26 17:01:28 "" LIEBER… 128 en Reute… YES
#> 10 <NA> 1987-02-26 17:08:27 "" GULF A… 134 en Reute… YES
#> # ℹ 40 more rows
#> # ℹ 8 more variables: lewissplit <chr>, cgisplit <chr>, oldid <chr>,
#> # places <named list>, people <lgl>, orgs <lgl>, exchanges <lgl>, text <chr>This can then be used with unnest_tokens() to, for example, find the most common words across the 50 Reuters articles, or the ones most specific to each article.
acq_tokens <- acq_td %>%
select(-places) %>%
unnest_tokens(word, text) %>%
anti_join(stop_words, by = "word")
# most common words
acq_tokens %>%
count(word, sort = TRUE)
#> # A tibble: 1,559 × 2
#> word n
#> <chr> <int>
#> 1 dlrs 100
#> 2 pct 70
#> 3 mln 65
#> 4 company 63
#> 5 shares 52
#> 6 reuter 50
#> 7 stock 46
#> 8 offer 34
#> 9 share 34
#> 10 american 28
#> # ℹ 1,549 more rows
# tf-idf
acq_tokens %>%
count(id, word) %>%
bind_tf_idf(word, id, n) %>%
arrange(desc(tf_idf))
#> # A tibble: 2,833 × 6
#> id word n tf idf tf_idf
#> <chr> <chr> <int> <dbl> <dbl> <dbl>
#> 1 186 groupe 2 0.133 3.91 0.522
#> 2 128 liebert 3 0.130 3.91 0.510
#> 3 474 esselte 5 0.114 3.91 0.445
#> 4 371 burdett 6 0.103 3.91 0.405
#> 5 442 hazleton 4 0.103 3.91 0.401
#> 6 199 circuit 5 0.102 3.91 0.399
#> 7 441 rmj 8 0.123 3.22 0.396
#> 8 162 suffield 2 0.1 3.91 0.391
#> 9 498 west 3 0.1 3.91 0.391
#> 10 467 nursery 3 0.0968 3.91 0.379
#> # ℹ 2,823 more rows5.3.1 Example: mining financial articles
Corpus objects are a common output format for data ingesting packages, which means the tidy() function gives us access to a wide variety of text data. One example is tm.plugin.webmining, which connects to online feeds to retrieve news articles based on a keyword. For instance, performing WebCorpus(GoogleFinanceSource("NASDAQ:MSFT")) allows us to retrieve the 20 most recent articles related to the Microsoft (MSFT) stock.
Here we’ll retrieve recent articles relevant to nine major technology stocks: Microsoft, Apple, Google, Amazon, Facebook, Twitter, IBM, Yahoo, and Netflix.
The following results were downloaded in January 2017, when this chapter was written, but as of June 2022 tm.plugin.webmining has been archived and is no longer available from CRAN.
library(tm.plugin.webmining)
library(purrr)
company <- c("Microsoft", "Apple", "Google", "Amazon", "Facebook",
"Twitter", "IBM", "Yahoo", "Netflix")
symbol <- c("MSFT", "AAPL", "GOOG", "AMZN", "FB",
"TWTR", "IBM", "YHOO", "NFLX")
download_articles <- function(symbol) {
WebCorpus(GoogleFinanceSource(paste0("NASDAQ:", symbol)))
}
stock_articles <- tibble(company = company,
symbol = symbol) %>%
mutate(corpus = map(symbol, download_articles))This uses the map() function from the purrr package, which applies a function to each item in symbol to create a list, which we store in the corpus list column.
stock_articles
#> # A tibble: 9 × 3
#> company symbol corpus
#> <chr> <chr> <list>
#> 1 Microsoft MSFT <WebCorps>
#> 2 Apple AAPL <WebCorps>
#> 3 Google GOOG <WebCorps>
#> 4 Amazon AMZN <WebCorps>
#> 5 Facebook FB <WebCorps>
#> 6 Twitter TWTR <WebCorps>
#> 7 IBM IBM <WebCorps>
#> 8 Yahoo YHOO <WebCorps>
#> 9 Netflix NFLX <WebCorps>Each of the items in the corpus list column is a WebCorpus object, which is a special case of a corpus like acq. We can thus turn each into a data frame using the tidy() function, unnest it with tidyr’s unnest(), then tokenize the text column of the individual articles using unnest_tokens().
stock_tokens <- stock_articles %>%
mutate(corpus = map(corpus, tidy)) %>%
unnest(cols = (corpus)) %>%
unnest_tokens(word, text) %>%
select(company, datetimestamp, word, id, heading)
stock_tokens
#> # A tibble: 105,666 × 5
#> company datetimestamp word id heading
#> <chr> <dttm> <chr> <chr> <chr>
#> 1 Microsoft 2017-01-17 12:07:24 microsoft tag:finance.google.com,clu… Micros…
#> 2 Microsoft 2017-01-17 12:07:24 corporation tag:finance.google.com,clu… Micros…
#> 3 Microsoft 2017-01-17 12:07:24 data tag:finance.google.com,clu… Micros…
#> 4 Microsoft 2017-01-17 12:07:24 privacy tag:finance.google.com,clu… Micros…
#> 5 Microsoft 2017-01-17 12:07:24 could tag:finance.google.com,clu… Micros…
#> 6 Microsoft 2017-01-17 12:07:24 send tag:finance.google.com,clu… Micros…
#> 7 Microsoft 2017-01-17 12:07:24 msft tag:finance.google.com,clu… Micros…
#> 8 Microsoft 2017-01-17 12:07:24 stock tag:finance.google.com,clu… Micros…
#> 9 Microsoft 2017-01-17 12:07:24 soaring tag:finance.google.com,clu… Micros…
#> 10 Microsoft 2017-01-17 12:07:24 by tag:finance.google.com,clu… Micros…
#> # ℹ 105,656 more rowsHere we see some of each article’s metadata alongside the words used. We could use tf-idf to determine which words were most specific to each stock symbol.
library(stringr)
stock_tf_idf <- stock_tokens %>%
count(company, word) %>%
filter(!str_detect(word, "\\d+")) %>%
bind_tf_idf(word, company, n) %>%
arrange(-tf_idf)The top terms for each are visualized in Figure 5.5. As we’d expect, the company’s name and symbol are typically included, but so are several of their product offerings and executives, as well as companies they are making deals with (such as Disney with Netflix).
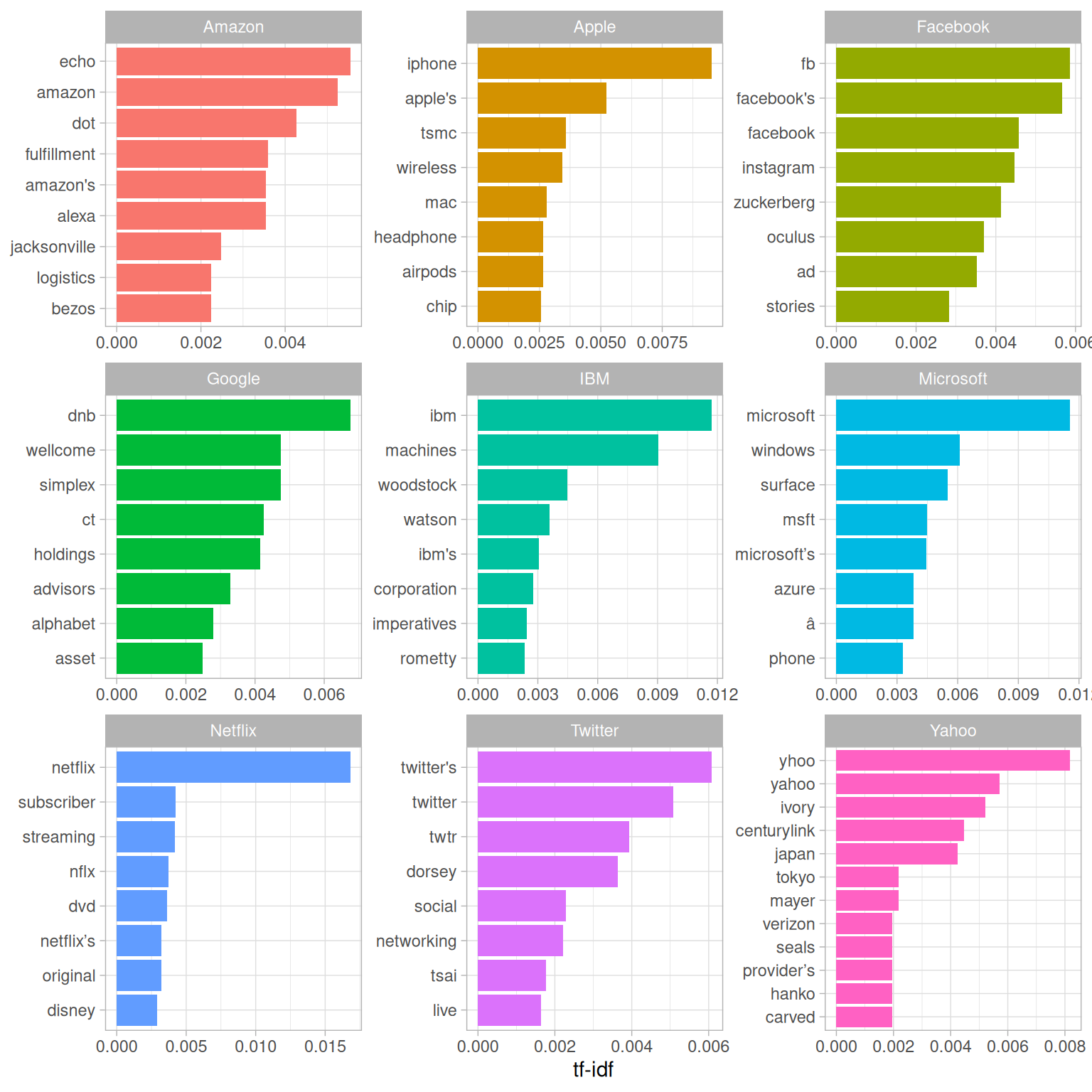
Figure 5.5: The 8 words with the highest tf-idf in recent articles specific to each company
If we were interested in using recent news to analyze the market and make investment decisions, we’d likely want to use sentiment analysis to determine whether the news coverage was positive or negative. Before we run such an analysis, we should look at what words would contribute the most to positive and negative sentiments, as was shown in Chapter 2.4. For example, we could examine this within the AFINN lexicon (Figure 5.6).
stock_tokens %>%
anti_join(stop_words, by = "word") %>%
count(word, id, sort = TRUE) %>%
inner_join(get_sentiments("afinn"), by = "word") %>%
group_by(word) %>%
summarize(contribution = sum(n * value)) %>%
slice_max(abs(contribution), n = 12) %>%
mutate(word = reorder(word, contribution)) %>%
ggplot(aes(contribution, word)) +
geom_col() +
labs(x = "Frequency of word * AFINN value", y = NULL)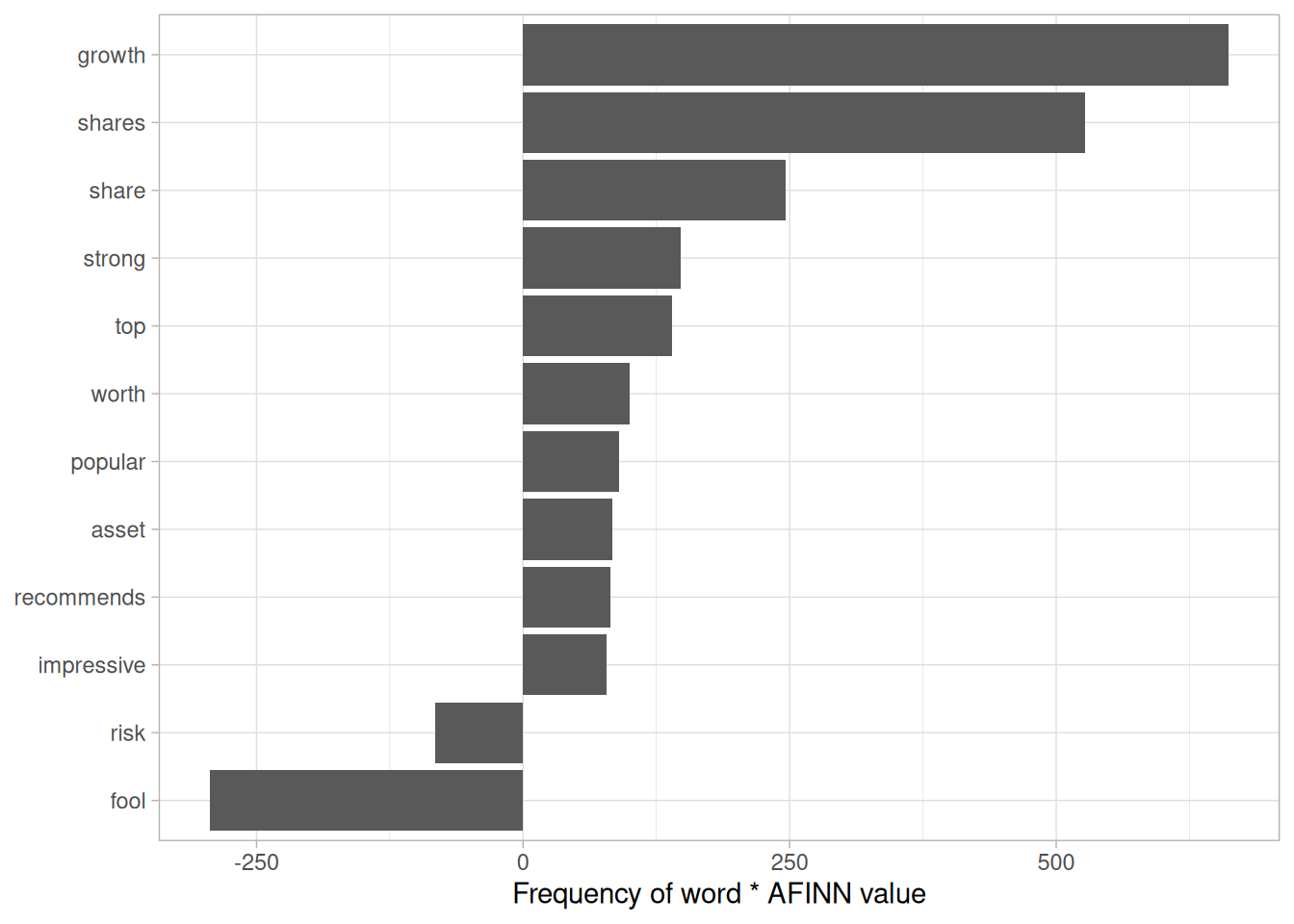
Figure 5.6: The words with the largest contribution to sentiment values in recent financial articles, according to the AFINN dictionary. The ‘contribution’ is the product of the word and the sentiment score.
In the context of these financial articles, there are a few big red flags here. The words “share” and “shares” are counted as positive verbs by the AFINN lexicon (“Alice will share her cake with Bob”), but they’re actually neutral nouns (“The stock price is $12 per share”) that could just as easily be in a positive sentence as a negative one. The word “fool” is even more deceptive: it refers to Motley Fool, a financial services company. In short, we can see that the AFINN sentiment lexicon is entirely unsuited to the context of financial data (as are the NRC and Bing lexicons).
Instead, we introduce another sentiment lexicon: the Loughran and McDonald dictionary of financial sentiment terms (Loughran and McDonald 2011). This dictionary was developed based on analyses of financial reports, and intentionally avoids words like “share” and “fool”, as well as subtler terms like “liability” and “risk” that may not have a negative meaning in a financial context.
The Loughran data divides words into six sentiments: “positive”, “negative”, “litigious”, “uncertain”, “constraining”, and “superfluous”. We could start by examining the most common words belonging to each sentiment within this text dataset.
stock_tokens %>%
count(word) %>%
inner_join(get_sentiments("loughran"), by = "word") %>%
group_by(sentiment) %>%
slice_max(n, n = 5, with_ties = FALSE) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col() +
facet_wrap(~ sentiment, scales = "free") +
labs(x = "Frequency of this word in the recent financial articles", y = NULL)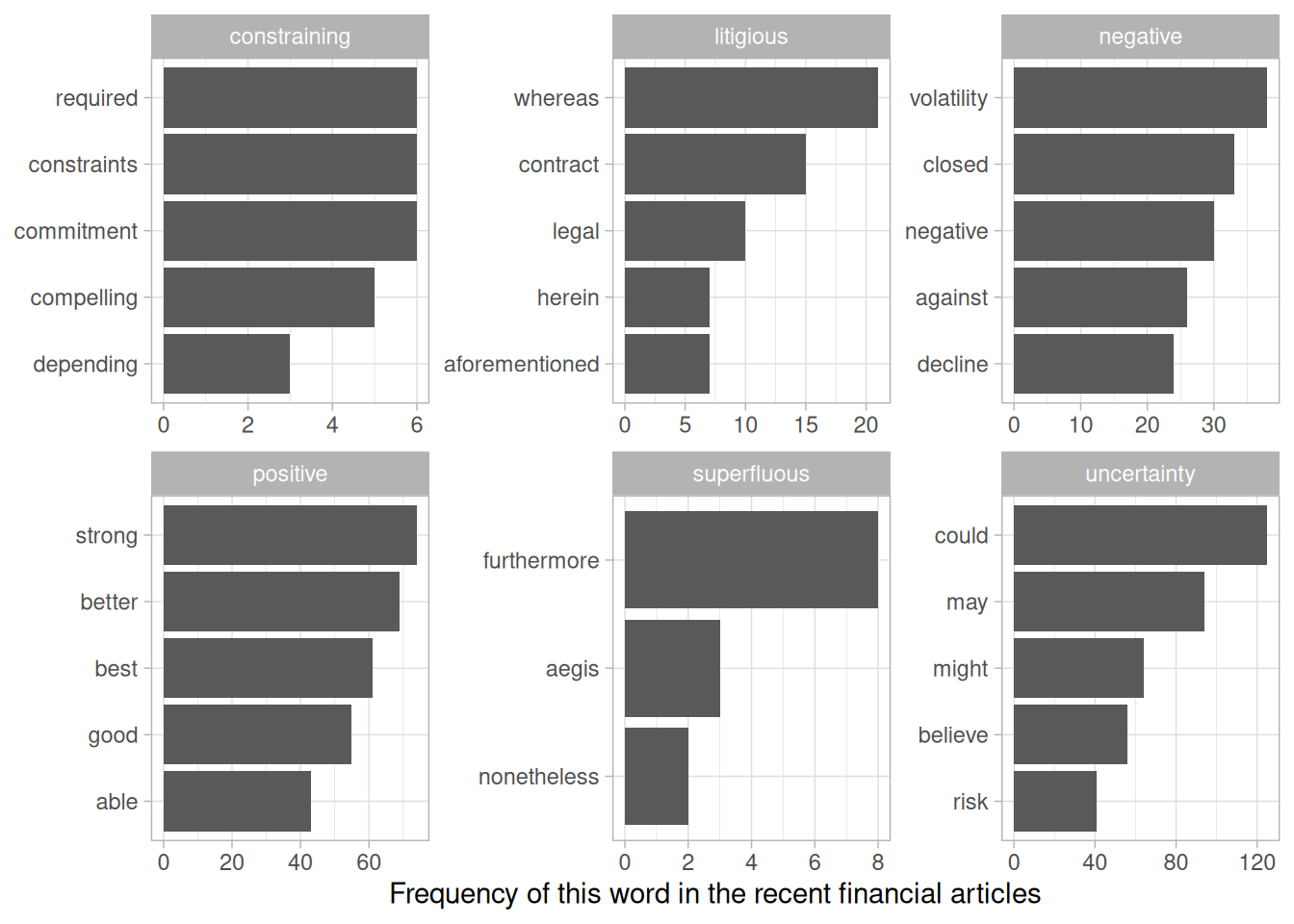
Figure 5.7: The most common words in the financial news articles associated with each of the six sentiments in the Loughran and McDonald lexicon
These assignments (Figure 5.7) of words to sentiments look more reasonable: common positive words include “strong” and “better”, but not “shares” or “growth”, while negative words include “volatility” but not “fool”. The other sentiments look reasonable as well: the most common “uncertainty” terms include “could” and “may”.
Now that we know we can trust the dictionary to approximate the articles’ sentiments, we can use our typical methods for counting the number of uses of each sentiment-associated word in each corpus.
stock_sentiment_count <- stock_tokens %>%
inner_join(get_sentiments("loughran"), by = "word") %>%
count(sentiment, company) %>%
pivot_wider(names_from = sentiment, values_from = n, values_fill = 0)
stock_sentiment_count#> # A tibble: 9 × 7
#> company constraining litigious negative positive superfluous uncertainty
#> <chr> <int> <int> <int> <int> <int> <int>
#> 1 Amazon 7 8 84 144 3 70
#> 2 Apple 9 11 161 156 2 132
#> 3 Facebook 4 32 128 150 4 81
#> 4 Google 7 8 60 103 0 58
#> 5 IBM 8 22 147 148 0 104
#> 6 Microsoft 6 19 92 129 3 116
#> 7 Netflix 4 7 111 162 0 106
#> 8 Twitter 4 12 157 79 1 75
#> 9 Yahoo 3 28 130 74 0 71It might be interesting to examine which company has the most news with “litigious” or “uncertain” terms. But the simplest measure, much as it was for most analysis in Chapter 2, is to see whether the news is more positive or negative. As a general quantitative measure of sentiment, we’ll use “(positive - negative) / (positive + negative)” (Figure 5.8).
stock_sentiment_count %>%
mutate(score = (positive - negative) / (positive + negative)) %>%
mutate(company = reorder(company, score)) %>%
ggplot(aes(score, company, fill = score > 0)) +
geom_col(show.legend = FALSE) +
labs(x = "Positivity score among 20 recent news articles", y = NULL)Figure 5.8: “Positivity” of the news coverage around each stock in January 2017, calculated as (positive - negative) / (positive + negative), based on uses of positive and negative words in 20 recent news articles about each company
Based on this analysis, we’d say that in January 2017 most of the coverage of Yahoo and Twitter was strongly negative, while coverage of Google and Amazon was the most positive. A glance at current financial headlines suggest that it’s on the right track. If you were interested in further analysis, you could use one of R’s many quantitative finance packages to compare these articles to recent stock prices and other metrics.
5.4 Summary
Text analysis requires working with a variety of tools, many of which have inputs and outputs that aren’t in a tidy form. This chapter showed how to convert between a tidy text data frame and sparse document-term matrices, as well as how to tidy a Corpus object containing document metadata. The next chapter will demonstrate another notable example of a package, topicmodels, that requires a document-term matrix as input, showing that these conversion tools are an essential part of text analysis.